
GPT-2やGPT-3が話題になることが多くなってきましたが、日本語の学習済みモデルもまだあまり公開されていないことから、日本語での実施例はまだまだ少ない気がしています。
そこで、正直なところいまだに機械学習ぜんぜんわからないのですが、色々便利なライブラリも公開されてることですし、それらを使えばGPT-2を使った日本語Twitter botを作れる気がしたので、実際に作ったよ!って感じの雑な振り返り記事になります。
事前学習とファインチューニング
今回、せっかくGPT-2を使うので「事前学習」と「ファインチューニング」の二段階で進めます。

まず大量の日本語データを「事前学習」することで、日本語の文書構造を学んでもらいます。
次に「ファインチューニング」を行うわけですが、ファインチューニングというのは、事前学習済みのモデルに対して、特定のタスクに特化したデータでの学習を行うことを言います。
ファインチューニングのメリットですが、学習済みのモデルに対しての追加学習という形になるので、少ないデータ量と短時間の学習でも狙ったタスクの精度を向上できるってわけです。
例えばbotを作るにしても、一度しっかりした事前学習済みモデルを作っておけば、男性っぽいbotでも、女性っぽいbotでも、狙いに合わせたデータでファインチューニングするだけで特徴のあるbotを作ることが出来るわけです。これは便利!
事前学習用のデータを集めます!
なにはともあれまずはデータが必要です。
事前学習のデータとしては日本語wikipediaコーパスを使うのが王道な気もしますが、いろいろ調べていたら「事前学習のデータも狙ったタスクに合わせて集めたほうが精度がよくなるよ」との声が聞こえてきました。
そんなものなのかな??今回の狙いは日本語Twitter botなので、試しに事前学習のデータもTwitterで集めることにします。wikipediaには無いTwitter的な文法もきっと覚えてくれるだろうし、確かにメリットはありそうな気がします。
ちなみにTwitterのツイートデータは基本的に配布が禁止されているので、自分でデータを集める必要があります。(なのでTwitter Developerに登録して、APIの利用申請して…とかの手順が必要になってくるのですが、ここでは本筋から外れるのではしょります)
ってことで、Twitter APIを使ってなるべく多くのツイートデータを収集します。とりあえずの目標として100万件を集めることにしました。

集め方ですが、ツイート情報の取得にはAPIのレートリミットがあるので、それを意識してデータ取集プログラムを書くのはちょっと面倒です。今回はtweepyというレートリミットのことを忘れさせてくれるライブラリを使ってツイート情報を集めました。このライブラリは呼び出し制限の上限までくると自動的に待ちに入るので、あまり上限を気にせずデータの収集が可能です!
あとはツイート情報を集める時に意識したいのは下記あたりでしょうか。。。
・botを避ける
・ハッシュダグの付いた投稿を避ける
・URLが入っている投稿を避ける
・写真や動画のある投稿を避ける
・他人に送っているリプライツイートも避ける
URL、写真、動画が付いている投稿は、そのURLや写真に対してのコメントがついていることが多いので、文章のみを取り出した時に意味不明になりがちなので除外した方がいいでしょう。
で、、、、スクリプトを動かして数日放置して、150万件ほどデータを集めました(けっこう時間かかった!)
150万件というとかなり多い感じもしますが、データサイズとしては130MBほどです(少ない!)。サイズを見た時は「この量でいいの?」との疑問も湧きましたが、そこは140文字のツイート生成用なのできっと大丈夫でしょう!って感じの勢い重視で気にせず次にいきます。
ファインチューニング用のデータを集めます
ファインチューニング用としては、狙ったタスクに合わせた「個性あるデータ」を集めます。
ここで集めるデータが完成するbotの性格のほぼ全てを決定付けるといっても過言ではない気がしているので、ここは少し注意しなければなりません。
そうそう、ここまで説明していませんでしたが、今回作ろうとしているbotは『進撃のえろ子さん』という漫画の主人公である新藤絵留子(27歳女性)のキャラbotになります。

なので成人女性っぽいアカウントのデータが欲しいところです。
Twitterで実際にそれっぽい条件の人を手動で地道に検索して10アカウントぐらい見つけました。次にその人たちのツイート情報を収集してツイート内容を形態素解析します。
使われている単語をまとめていくと、なんなーくですが、まず男性は使わないと思われる単語(例えばコスメとか)がいくつも見えてきます。
で、次にここで抽出した「特徴的な単語を使っているアカウントを見つけて、そのツイートを集める」スクリプトを書いて、狙ったタスクに合わせた個性あるデータを集めました!件数的には10万件いかないぐらいです。
これでデータに関しては一応そろったので、学習させる前に余分な改行やスペースなどを除去したり、よくある自然言語の前処理も済ませます。
Hugging Faceを使います!
いよいよGPT-2のモデルを作る学習を始めます。
Hugging Faceという自然言語処理の最新技術を集めたオープンソースの素敵ライブラリがあるので、これを使わさせて頂きます。

GPT-2なら本家のOpenAIのライブラリを使って学習しないの?と聞かれそうな気もしますが、以前個人的にBERTを使った文書分類をした時にHugging Faceを使ったこともあり、馴染みがあるので深く考えず今回もHugging Faceでいきます!
Google Colabで学習します!
ライブラリはHugging Faceにしましたが、次は学習する環境ですね…。
なるべくお金を使わず済ませたいところなので、Google Colabの1択になります。
Google Colabは凄すぎますね。なんとGPUが無料で使えます。
12時間で強制的にセッションが切られたりと色々制限はありますが、やはり無料でGPUが使えるという恩恵は大きいです。
Google Colabを使うときの注意点ですが、あえて言うならばGPUガチャを意識することですかね…何種類かのGPUがあるようでして、どのGPUが割り当てられるかは完全に運みたいです。
どのGPUが割り当てられたかは
!nvidia-smi
で確認できるので、ランタイムのタイプをGPUに切り替えたあとは必ず実施しましょう。(この記事を書いている2020年9月時点ではTesla P100-PCIEが来たら大当たりです)
あと、GPUメモリの量にも注意してください。GPUによっては割り当てられるメモリ量が違うこともあったので、同じ処理でも前回は動いたのに今回は動かないとか起きてハマります。(ハマった)
wandbも使います!
wandbという実験管理ツールがあるので使いましょう。超便利です。Hugging Faceはwandbと簡単に連携ができるので、学習経過のチェックに重宝します。
無料ですのでアカウントを作っておくことをオススメします。
Tokenizerも作っておきましょう!?
日本語の入力文字列をトークンに分割して処理してもらうために、日本語データに対応したTokenizerを作ります
作り方はHugging Faceが用意しているノートブックがあるので、これを見て作るとよい気がします。
Tokenizerはのちのち使い回せることを考えると素直に日本語Wikipediaのデータを使って作るほうがよいかもしれません。
いよいよ学習を始めます!
まずは事前学習です。
データの準備をした後にGoogle Colabで下記の通りポチポチしていけば学習が始まると思います。(データのpathとかは適時読み替えてください)
# wandbと接続 !pip install --upgrade wandb import wandb wandb.login()
# huggingface関連 !pip install transformers !git clone https://github.com/huggingface/transformers.git !pip install ./transformers/. !pip install -r ./transformers/examples/requirements.txt !pip install pyarrow==0.16.0
# googleドライブと接続
from google.colab import drive
drive.mount('./drive')
# 学習の実施 !python /content/transformers/examples/language-modeling/run_language_modeling.py \ --output_dir="/content/drive/My Drive/_develop/output/" \ --model_type=gpt2 \ --config_name=gpt2 \ --do_train \ --train_data_file="/content/drive/My Drive/_develop/text_data/tweet_data.txt" \ --tokenizer_name="/content/drive/My Drive/_develop/TOKENIZER" \ --logging_steps=100 \ --save_steps=10000 \ --save_total_limit=1 \ --overwrite_output_dir \ --per_device_train_batch_size=8 \ --block_size=128 \ --num_train_epochs=32 \
Google Colabは1日12時間という使用制限があるので、この学習量ですと毎日少しずつ学習させていく形になります。今回は地道に1週間ほど学習させてみました。
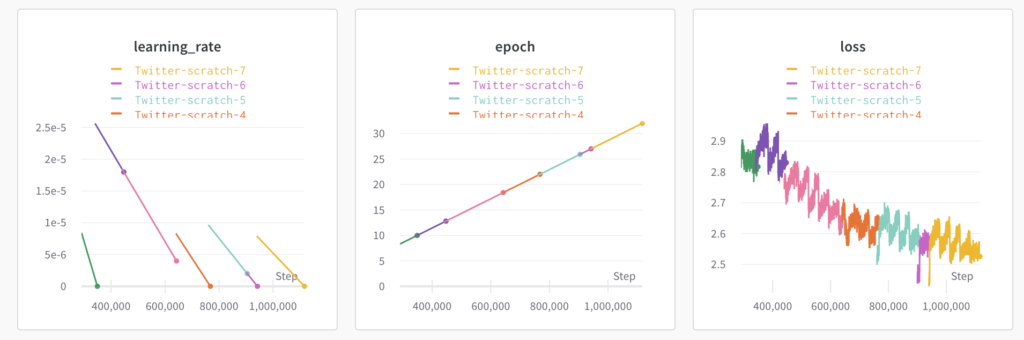
なお、12時間でセッションが切れるとデータも全て消えてしまうので、チェックポイントのデータはGoogleドライブに保存する形にしています。
私はたまたまGoogleドライブに課金していて容量が多く使えたので問題ありませんでしたが、無料枠の15GBだと空き容量に気をつけながら学習したほうがよさそうです。
それと上記のコマンド例はnum_train_epochs=32となってますが、まずは=1で実施して1epochあたりどれぐらい時間がかかるかを先に一度確認して学習パラメーターを気にしたほうがいいかも。
なにはともあれ、この学習が終われば事前学習済みのモデルができてるはずです!!!
ちょっと試しに動かしてみましょう!
無事にモデルが出来たら早速ですが動かしてみましょう!
!python /content/transformers/examples/text-generation/run_generation.py \ --model_type=gpt2 \ --model_name_or_path=<作成したモデルのpath>
promptで入力を要求されるので適当な文章を入れて、日本語のツイートっぽい文章が生成されたら成功です!

各種パラメータもオプション指定できるので、色々と試してみると面白い結果になりますよ。
ファインチューニング実施
基本的には事前学習の時とそんなに変わりません。パラメータとしてはmodel_name_or_pathに事前学習させたモデルを指定して、 train_data_fileにはファインチューニング用に用意したテキストファイルを指定すれば、OKです。
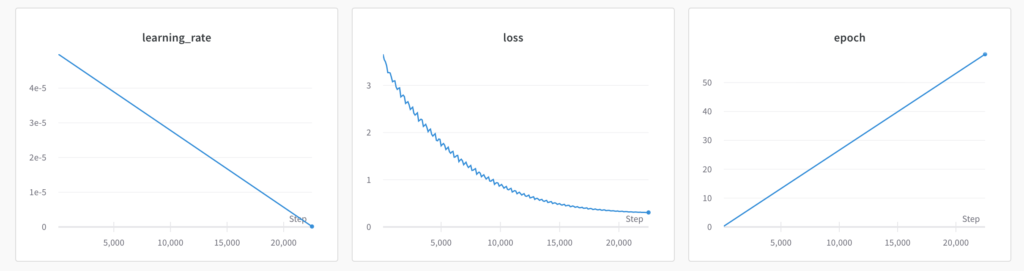
num_train_epochsはお好みで。ファインチューニングは用意したデータ量によりますが基本的には短時間でサクッと終わると思います。
botのツイートとして利用するには
ここまでの作業でほぼ無限にツイート文章を生成してくれるモデルが完成したわけですが、このモデルをbotに適用するには大きく二つのパターンがあると思っています。
オーソドックスなのは「事前にツイート文章を大量生成してツイート文に使う」だと思います。GPU環境で1万件ぐらい先に文章を作っておけばbotを動かすサーバーには負荷かかりません。
もう一つの方法は実際にツイートするタイミングに合わせて「都度リアルタイムに文章を生成する」です。こちらはVPSとかに環境作ったり、大きなモデルを読み込むのにメモリも気にしたりといろいろ面倒なことが多いですが、どんな文章が出てくるか事前に確認できないので開発者にもわからない楽しさがあります。
仕事で作るようなシステムなら前者がいいのかもしれませんが、今回は仕事に見せかけた趣味ですので後者を選んでみました。
とまぁ、そんな感じで完成したTwitter botがこちらになります!
https://twitter.com/ero_ko_200
いくつかGPT-2によって生成されたツイート文も載せておきます。
変な文章になることも多いですが、「えろ子さん」というキャラの特性も出てますし、時々人間と見分けのつかないツイートもするので見ていて楽しいです。
パクツイ注意
ファインチューニング用のデータが少ないと、時々元データとかなり近い、もしくは完全に同じ文章を生成してしまうことがあります。
これだとパクツイになってしまってちょっと困った感じになるので、ファインチューニング用の学習データと生成した文章を比較して文章の類似度が高いときは、その生成文は捨てる処理とか入れたほうがいいかもしれません。(二つの文章の類似性の検証方法とかなると、PHPのsimilar_text関数とかそのあたりがメジャーなんですかね?それともDoc2Vecとか使う?)
最後に
かなり対象範囲が狭い記事な気がするので誰の役に立つのかわからない内容でしたが、この記事が数少ない誰かのお役に立てたのならば幸いです。
もし、少しでも参考になったという方がいたら『変女』と『進撃のえろ子さん』という最高に面白い漫画があるのでそれらを買って楽しんでもらえたら私としては十分すぎるほどに満足です!
